The data analyst project was initiated by a business request to create a sales report for sales managers at an executive level. In order to meet the business's requirements, a set of user stories was identified to guide the project's development and ensure that the acceptance criteria were met.


In this project, I will work on the "SONAR CSV" dataset from Kaggle. This dataset contains information about sonar returns from various objects and I will be using python libraries such as numpy, pandas, and sklearn to analyze the data and build a predictive model using Logistic Regression. I will be evaluating the model's performance using the accuracy_score metric. I am excited to use these tools and techniques to explore the relationships within the data and create a model that can accurately predict whether the object is a rock or mine.

I am working on a data analysis project using the "loan_train.csv" dataset from IBM Developer Skills Network. This dataset contains information about loan applicants and I will be using python libraries such as numpy, pandas, and sklearn to analyze the data and build predictive models using KNN, Decision Tree, SVM, and Logistic Regression. I will be evaluating the performance of these models using metrics such as Jaccard, F1 score, and Logloss. I am excited to use these tools and techniques to explore the relationships within the data and create accurate models for predicting loan approval.

I am analyzing the "Social Media Influences on shopping" dataset to uncover trends in millennial shopping behavior and the impact of social media on their purchasing decisions. Using python libraries such as numpy, pandas, matplotlib, and seaborn, I am uncovering insights that will provide valuable information for businesses targeting this generation.
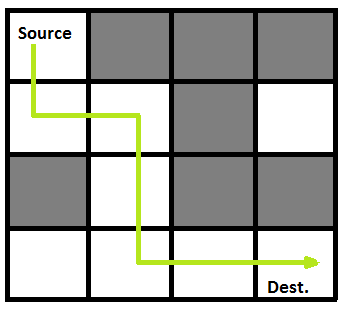
I developed a project using C++ to efficiently compute the quickest paths across a matrix. Leveraging dynamic programming and backtracking, the solution identifies the shortest traversal time from the matrix's top row to each position on the bottom row, considering cell time values and applying penalties for diagonal moves. The approach breaks the task into subproblems, iteratively calculating the minimum distance from preceding cells while tracking the optimal path.

This project is designed to build a classification algorithm to predict whether a particular movie on Rotten Tomatoes is labeled as 'Rotten', 'Fresh', or 'Certified-Fresh'. The main models used in this project are Decision Tree and Random Forest.